- drop 함수

이 데이터프레임에서 race_ethnicity 행의 'All' 값이 속한 행만 삭제하고 싶으면 어떻게 해야 할까?
drop 함수를 쓰지 않으면 condition=df['race_ethnicity']!='All'이라는 조건을 적용하는 방법도 있지만,, 그래도 함수를 이용해서 풀어보자.
특정한 label이나 해당 축을 삭제하고 싶을 때 쓰는게 drop 함수이며,
기본적인 형태는 df.drop('row or column 이름', axis='index or 0' or 'columns or 1') 이다.
index 값을 지우고 싶을 땐 axis=0, column을 지우고 싶을 땐 axis=1을 붙어주면 되는데, axis를 생략하고 싶으면 df.drop(index='row이름') / df.drop(columns='column이름') 이런식으로 쓰자.
삭제하고 싶은 row나 column의 수가 둘 이상일 땐 ['cow','bird'] 이런 식으로 중괄호 붙여주기.
- 이제 위의 사례를 수행해보자. 'race_ethnicity'가 'All'인 행들을 모두 삭제하려면 먼저 이 행들의 index 번호를 알아야 한다. column 값들은 모두 index를 축으로 정렬되어 있기 때문이다.
A = df2[df2['race_ethnicity'] == 'All'].index-> Int64Index([8, 9, 19, 20, 30, 31, 41, 42], dtype='int64')
A의 출력값으로 위와 같이 All이 속한 모든 index 번호가 정렬되어 나오는 것을 확인할 수 있다.
- 이제 A를 drop 함수에 적용하려면 axis를 index로 걸어서 해야 한다. A가 'All'들의 index 번호를 보유하고 있기 때문이다.
어떤 특정한 조건을 걸고 싶을 땐 A 자리에 데이터프레임이 아닌 인덱스를 제공해야 에러없이 정상적으로 작동하는 것을 꼭 기억하자.
df2.drop(A,axis='index',inplace=True)
위의 코드들을 차례대로 실행하고 다시 df2를 출력해보면
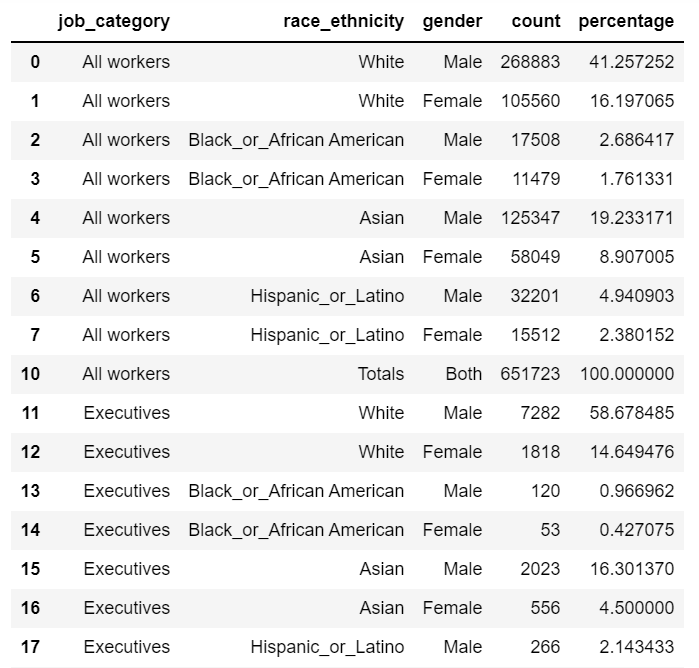
이렇게 8, 9, 19, 20, 30, 31, 41, 42번의 'All'이 포함된 모든 열이 삭제된 걸 확인할 수 있다.
'Programming > python' 카테고리의 다른 글
| 파이썬 python drop, rename, isin 함수로 데이터 정제하기 -1 (0) | 2021.07.19 |
|---|---|
| 판다스 pandas IQR 활용해서 이상점(outlier) 찾고 삭제하기 (0) | 2021.07.12 |
| 판다스 axis 매개변수 개념 완벽정리 (0) | 2021.07.01 |
| 파이썬 python groupby 함수 이용해서 여성 비율이 높은 직업 알아보기 (0) | 2021.06.25 |
| DataFrame과 for문 이용하여 큰 데이터 다루기 (0) | 2021.05.27 |



