어떤 데이터를 분석하고 시각화하려 할 때 다른 값들과 확연한 차이가 나거나 비정상적인 이상점이 존재할 때 데이터가 의미하는 바를 제대로 분석하지 못할 수도 있다.
그래서 데이터 분석의 목적에 따라서 이상점을 삭제하거나 수정해야 한다.
이상점을 삭제하려면 우선 이상점을 찾아야 한다.

박스 플롯을 보면 데이터의 분포와 데이터들 사이에서 이상점의 개별적인 이상치를 볼 수 있다.
박스 플롯의 구성은 이렇다.

그래프 바깥에는 이상점이 표시된다. 즉, 데이터의 최댓값과 최솟값을 넘어가는 위치에 있는 값을 이상점이라 할 수 있다.
그리고 Q1은 제 1사분위로, 25%의 위치를 가르킨다.
Q2는 제 2사분위로, 50%의 위치인 중앙값(median)을 가르킨다.
Q3은 제 3사분위로, 75%의 위치를 가르킨다.
Q1 - 1.5 * IQR = 최솟값, Q3 + 1.5 * IQR = 최댓값
->이상점 기준 공식이다. 이 때 결정된 최솟값보다 작거나, 최댓값보다 큰 값을 이상점으로 간주한다. boolean 활용해서 구할 수 있다. 아래 코드보기.
참고로 IQR은 InterQuartile Range의 줄임말로, Q1과 Q3 사이에 있는 수치이다. 박스 플롯의 기본이 되는 수치이다.
즉, IQR = Q3 - Q1
이제 이상점을 찾는 공식을 알았으니 응용해서 이상점을 찾고 삭제해보자.
아시아 국가들의 최근 코로나 현황을 모아놓은 데이터셋이다.

코로나 확진자 수, 사망자 수, 완치자, 총 인구 수 등 코로나 현황 분석을 위한 여러 컬럼들이 있다.
총 인구 수와 확진자 수의 산점도를 그려보자.
import pandas as pd
%matplotlib inline
covid=pd.read_csv('data/Latest Covid-19 Data in Asia.csv')
covid.plot(kind='scatter',x='Population',y='Total Cases')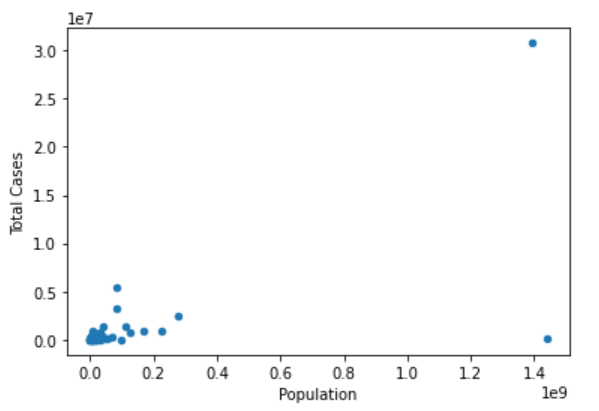
보다시피 인구 수가 다른 국가에 비해 월등히 높은 몇몇 국가들의 데이터 때문에 그래프가 잘 보이지 않는다.
인구 수를 기준으로 75% 지점에서 1.5*IQR을 더한 것보다 많은 인구 수를 가진 국가를 제거하고 산점도 그래프를 다시 그려보자.
먼저 IQR을 구해야 하는데, describe() 메소드로 데이터의 최솟값, 최댓값, 중앙값, 25% 지점, 75% 지점 등 여러 통계값을 확인할 수 있다.
covid['Population'].describe()
>>>
count 4.900000e+01
mean 9.477503e+07
std 2.814899e+08
min 4.417360e+05
25% 5.221495e+06
50% 1.695384e+07
75% 5.131411e+07
max 1.439324e+09
Name: Population, dtype: float64
>>>'Population' 열의 통계값들을 쭉 나열한 결과가 나왔다. 이 중 25% 지점과 75% 지점의 값들을 Q1과 Q3 변수에 할당해줘서 IQR 을 구할 수 있다. 하지만 quantile() 함수를 쓰면 일일히 확인하지 않아도 25% 값과 75% 값을 구할 수 있다.
q1=covid['Population'].quantile(0.25)
q2=covid['Population'].quantile(0.5)
q3=covid['Population'].quantile(0.75)
iqr=q3-q1
iqr
>>>
46092611.0
>>>
quantile의 파라미터로 구하고 싶은 값을 넣어주면 그 값에 해당하는 숫자가 리턴된다.
그 값을 q1과 q3 변수에 할당해주고 위에서 언급했던 IQR = Q3 - Q1 공식을 적용해서 IQR 값을 구했다.
총 인구 수 열의 IQR 값은 46092611.0 으로 나왔다.
condition=covid['Population']>q3+1.5*iqr
covid[condition]우리는 인구 수가 많은 국가들을 제거해야 하니 75% 지점인 q3에서 1.5*iqr 많은 인구 수를 가진 국가들(최댓값)을 찾고 이 값보다 인구 수가 많은 국가들을 구해 condition 변수에 저장한다.
그리고 이 조건을 covid 데이터프레임에 적용하면

총 인구 수가 q3+1.5*iqr 보다 많은 인덱스 값들이 쫙 나온다.
방글라데시, 중국, 인도, 인도네시아, 일본, 파키스탄이 걸렸다. 이제 이 행들만 삭제하면 된다.
a=covid[condition].index
covid.drop(a,inplace=True)a를 실행하면 covid[condition]의 모든 인덱스 번호가 리턴된다. Int64Index([4, 8, 12, 13, 17, 31], dtype='int64')
이 인덱스들을 지워야 하니 drop의 파라미터로 a를 넣어준다. 참고로 drop 함수는 기존 데이터프레임을 건들지 않으니 결과값을 df에 적용하고 싶으면 inplace=True 꼭 해주기.
covid.plot(kind='scatter',x='Population',y='Total Cases')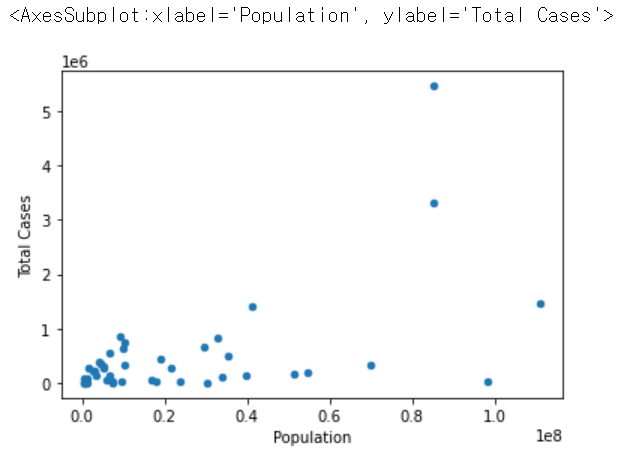
6개의 국가들을 제거하고 다시 산점도 그래프를 그려보면 제거하지 않았을 때 그렸던 그래프보다 훨씬 보기 좋다.
산점도를 보니 점들이 일관성있진 않은 것 같다.
일관된 패턴 발견되지 않음. 인구가 많으면 그만큼 확진자 수도 많아지겠지만 꼭 그렇지만도 않은게 이번 분석의 결론..
<전체보기>
import pandas as pd
%matplotlib inline
covid=pd.read_csv('data/Latest Covid-19 Data in Asia.csv')
q1=covid['Population'].quantile(0.25)
q3=covid['Population'].quantile(0.75)
iqr=q3-q1
condition=covid['Population']>q3+1.5*iqr
a=covid[condition].index
covid.drop(a,inplace=True)
covid.plot(kind='scatter',x='Population',y='Total Cases')'Programming > python' 카테고리의 다른 글
| 파이썬 python matplotlib 으로 노년 구직자의 희망직종명 파이차트 그리기-2 (0) | 2021.07.22 |
|---|---|
| 파이썬 python drop, rename, isin 함수로 데이터 정제하기 -1 (0) | 2021.07.19 |
| 판다스 axis 매개변수 개념 완벽정리 (0) | 2021.07.01 |
| 파이썬 python groupby 함수 이용해서 여성 비율이 높은 직업 알아보기 (0) | 2021.06.25 |
| 파이썬 python drop 함수 활용해서 행 삭제하기 (0) | 2021.06.07 |



