모든 데이터가 csv 형식같은 rectanglar data로 되어 있으면 데이터프레임화하기 편하지만, 데이터가 HTML, XML, JSON, YAML 등 여러 포맷의 hierachical data로 되어 있는 게 현실이다.
그래서 이런 데이터들을 파싱해서 파이썬으로 불러오고 어떻게 분석해야 하는지 정리해보겠다 !
위 데이터셋은 미국 국회의원들의 이름, 생년월일, 소속당, 전화번호 등 자세한 정보가 들어있는 yaml 파일이다.
https://github.com/unitedstates/congress-legislators/blob/main/legislators-current.yaml
깃헙에서 가져온건데, 파싱한 코드는 아래와 같다.
import requests
from pathlib import Path
legislators_path = 'legislators-current.yaml'
base_url = 'https://github.com/unitedstates/congress-legislators/raw/dc6fde4ed65f88edf11568d0522eca17b439f447/'
def download(url, path):
"""Download the contents of a URL to a local file."""
path = Path(path)
if not path.exists():
print('Downloading...', end=' ')
resp = requests.get(url)
with path.open('wb') as f:
f.write(resp.content)
print('Done!')
download(base_url + legislators_path, legislators_path)데이터셋이 저장되어 있지 않다면 requests의 get() 함수를 이용하여 url 서버로부터 응답을 요청하고 응답 객체를 돌려 받는다.
그런 다음 응답받은 객체들 중 content 요소를 with.open() 함수를 통해 열린 f (file object)에 write한 다음, Done! 이라는 텍스트가 뜨며 우리가 정의한 download 실행이 종료되며 위에 첨부한 yaml 파일이 다운로드된다.
이 파일을 주피터 노트북 환경에서 여는 코드로 yaml.safe_load()를 쓴다.
import yaml
legislators = yaml.safe_load(open(legislators_path,encoding='UTF-8'))
len(legislators)
>>>
539legislators
>>>
[{'id': {'bioguide': 'B000944',
'thomas': '00136',
'lis': 'S307',
'govtrack': 400050,
'opensecrets': 'N00003535',
'votesmart': 27018,
'fec': ['H2OH13033', 'S6OH00163'],
'cspan': 5051,
'wikipedia': 'Sherrod Brown',
'house_history': 9996,
'ballotpedia': 'Sherrod Brown',
'maplight': 168,
'icpsr': 29389,
'wikidata': 'Q381880',
'google_entity_id': 'kg:/m/034s80'},
'name': {'first': 'Sherrod',
'last': 'Brown',
'official_full': 'Sherrod Brown'},
'bio': {'birthday': '1952-11-09', 'gender': 'M', 'religion': 'Lutheran'},
'terms': [{'type': 'rep',
'start': '1993-01-05',
'end': '1995-01-03',
'state': 'OH',
'district': 13,
'party': 'Democrat'},
{'type': 'rep',
'start': '1995-01-04',
'end': '1997-01-03',
'state': 'OH',
'district': 13,
'party': 'Democrat'},
{'type': 'rep',
'start': '1997-01-07',
'end': '1999-01-03',
'state': 'OH',
'district': 13,
'party': 'Democrat'},
{'type': 'rep',
'start': '1999-01-06',
'end': '2001-01-03',
'state': 'OH',
'district': 13,
'party': 'Democrat'},
.
.
.이렇게 야몰 파일이 539개의 파이썬 딕셔너리 형식으로 옮겨 온 것을 확인할 수 있다.
야몰은 Hashmap(key - value) 이 기본 구조인데, 파이썬의 딕셔너리도 중괄호{}를 이용하여 {key : value} 형태로 선언하고 또 각각의 쌍은 콤마(,)로 구분한다. key-value 쌍으로 이루어져 있다는 점에서 야몰과 딕셔너리는 비슷한 형태를 띈다.
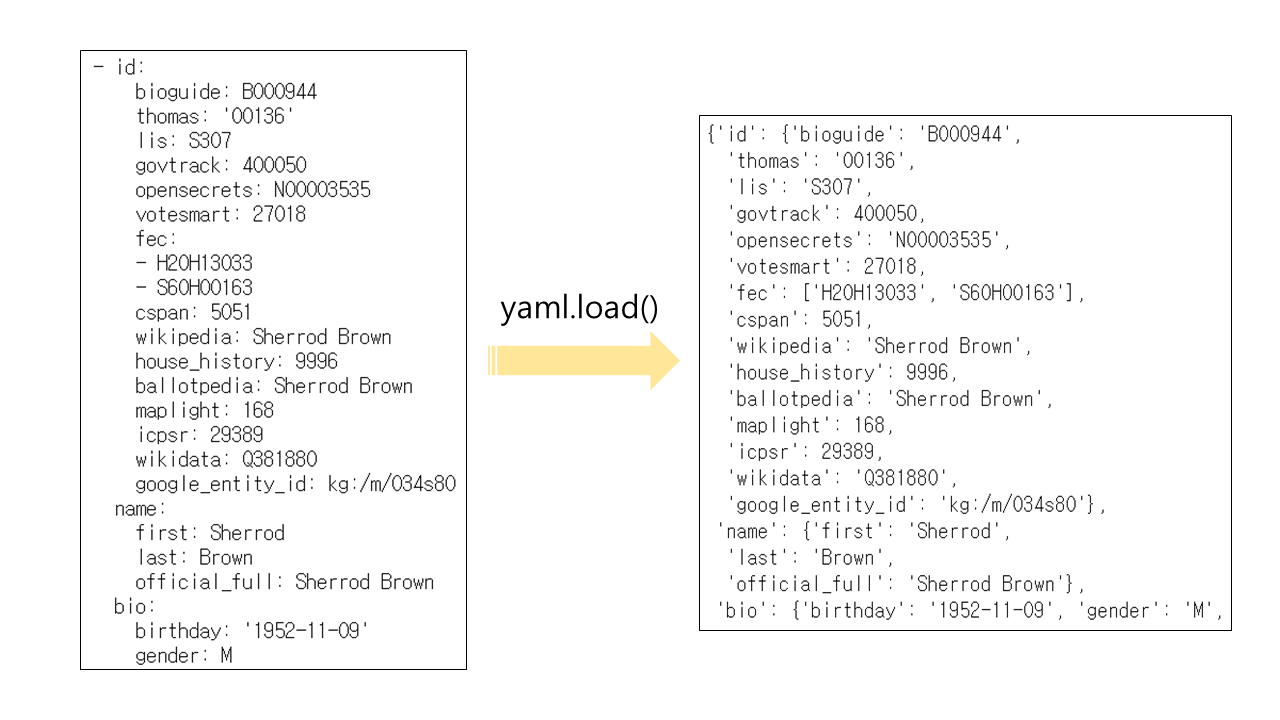
기존 미국 국회의원들의 정보가 담긴 야몰 파일과 이것을 yaml.load()해서 파이썬 딕셔너리 형태로 바꾼 결과를 비교해보면
1. 딕셔너리를 선언하는 중괄호 {}가 추가되었고,
2. 야몰 파일은 " "없이 문자열 작성이 가능한 반면, 딕셔너리는 문자열에 따옴표 표시가 자동적으로 추가되어 나타났다.
3. 또한, 야몰은 '-'(하이픈)으로 배열 원소를 나타내는 반면, 딕셔너리는 배열 원소에 접근할 때 사용하는 []을 이용해 하이픈을 대신했다.
야몰의 해쉬맵 형식이 각 label 별로 값들이 파이썬 딕셔너리 포맷으로 바뀌어서 파싱된다.
딕셔너리 중 특정 값만 추출하고 싶을 때 인덱싱
x=legislators[0]
x['id']
>>>
{'bioguide': 'B000944',
'thomas': '00136',
'lis': 'S307',
'govtrack': 400050,
'opensecrets': 'N00003535',
'votesmart': 27018,
'fec': ['H2OH13033', 'S6OH00163'],
'cspan': 5051,
'wikipedia': 'Sherrod Brown',
'house_history': 9996,
'ballotpedia': 'Sherrod Brown',
'maplight': 168,
'icpsr': 29389,
'wikidata': 'Q381880',
'google_entity_id': 'kg:/m/034s80'}x['id']로 배열을 인덱싱하면 legislators의 첫 번째 array 요소들 중에 'id' 키에 포함되는 모든 값들이 추출된다.
x['name']
>>>
{'first': 'Sherrod', 'last': 'Brown', 'official_full': 'Sherrod Brown'}
>>>
x['bio']
>>>
{'birthday': '1952-11-09', 'gender': 'M', 'religion': 'Lutheran'}
>>>이렇게 딕셔너리 인덱싱 할 땐 숫자로는 안 된다.
위에 legislators[0] 인덱싱은 legislators라는 큰 배열을 인덱싱한 것이라서 숫자가 가능했지만,
딕셔너리는 key 값으로 인덱싱하기 때문에 위치번호로는 인덱싱이 안 된다는 걸 주의해야 한다. key값으로만 된다!
응용) 국회의원들의 나이 데이터프레임화 하기
'bio' key의 value에는 생년월일, 성별, 종교 정보가 기재되어 있다.
생년월일 정보를 추출해서 현재 날짜에서 빼주면 현재 나이가 나올 것이다.
from datetime import datetime
def to_date(s):
return datetime.strptime(s, '%Y-%m-%d')
to_date(x['bio']['birthday'])
>>>
datetime.datetime(1952, 11, 9, 0, 0)
# 1952,11,9는 string 형태, 뒤에 0,0은 시간. 시간인자 생략할 경우 0으로 나옴datetime.strptime()은 시간 형식의 문자열을 datetime 형식으로 만들 때 사용한다.
'bio' 키의 값이자 생년월일의 키인 'birthday' 를 인덱싱하고 생년월일 정보를 '%Y-%m-%d' 형태로 저장하는 to_date 함수를 정의한다.
그 다음 파라미터로 x['bio']['birthday'] 를 넣어주면 의원의 생년월일 정보가 년, 월, 일에 각각 지정된다.
leg_df = pd.DataFrame(
columns=['id', 'first', 'last', 'birthday'],
data=[[x['id']['bioguide'],
x['name']['first'],
x['name']['last'],
to_date(x['bio']['birthday'])] for x in legislators])
leg_df.head()
딕셔너리를 인덱싱해서 각각 컬럼에 맞는 값으로 지정해 데이터프레임으로 만들었다.
그리고 마지막에 for문을 돌려서 legislators에 기재된 모든 국회의원의 정보가 leg_df에 들어가도록 한다.
야몰 데이터를 이렇게 df로 만들면 된다.
datetime.now() - leg_df.loc[0, 'birthday'] # 현재 시각에서 Sherrod가 태어난 날짜를 뺌. Sherrod가 현재까지 산 총 날짜.
>>>
Timedelta('25197 days 18:14:09.605883')
>>>
leg_df['age'] = (datetime.now() - leg_df['birthday']).apply(lambda age: age.days/365)
leg_df.head()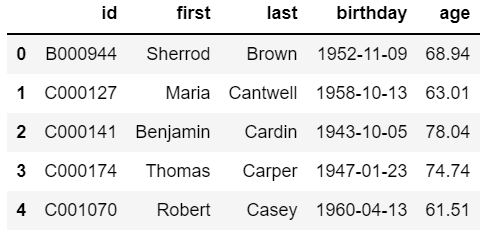
현재 날짜에서 첫 번째 정보의 주인인 Sherrod의 생년월일을 빼면 25197 days라는, Sherrod가 살아온 날들이 출력된다.
이것과 같이 leg_df['age']로 'birthday' 컬럼 옆에 'age' 컬럼이 생성되고, 현재 날짜에서 의원들의 생년월일을 뺀 값을 365로 나눈 결과값이 할당된다.
plt.figure(figsize=(3,6))
sns.violinplot(leg_df['age'],orient='v');
'age' 칼럼을 바이올린플롯으로 시각화해서 간단하게 나타내보면
의원들의 나이가 60대에서 70대 사이에 몰려있다는 걸 알 수 있다.
* 전체보기 *
import requests
from pathlib import Path
import yaml
from datetime import datetime
legislators_path = 'legislators-current.yaml'
base_url = 'https://github.com/unitedstates/congress-legislators/raw/dc6fde4ed65f88edf11568d0522eca17b439f447/'
def download(url, path):
"""Download the contents of a URL to a local file."""
path = Path(path)
if not path.exists():
print('Downloading...', end=' ')
resp = requests.get(url)
with path.open('wb') as f:
f.write(resp.content)
print('Done!')
download(base_url + legislators_path, legislators_path)
legislators = yaml.safe_load(open(legislators_path,encoding='UTF-8'))
x=legislators[0]
x['id']
def to_date(s):
return datetime.strptime(s, '%Y-%m-%d')
to_date(x['bio']['birthday'])
leg_df = pd.DataFrame(
columns=['id', 'first', 'last', 'birthday'],
data=[[x['id']['bioguide'],
x['name']['first'],
x['name']['last'],
to_date(x['bio']['birthday'])] for x in legislators])
datetime.now() - leg_df.loc[0, 'birthday']
leg_df['age'] = (datetime.now() - leg_df['birthday']).apply(lambda age: age.days/365)
이렇게 야몰 데이터를 웹으로부터 가져오고 원하는 분석을 하기 위해 데이터프레임화 해봤다.
야몰 파일이 파이썬 딕셔너리 형태로 전환됐을 때 어떤 형식으로 이루어져 있는지를 유심히 보고,
그에 알맞는 인덱싱 방법을 사용해서 원하는 데이터를 추출하는 게 중요한 것 같다.
그리고 yaml이나 json처럼 계층구조를 갖는 데이터를 rectangular data 형식으로 변환하는 연습도 계속 해야 할 것 같다.
'Programming > python' 카테고리의 다른 글
| 파이썬 선택 정렬 알고리즘(selection sort) 개념과 예제 (0) | 2022.06.06 |
|---|---|
| 파이썬 정규표현식(Regular Expression)과 예제 살펴보기 (0) | 2022.02.17 |
| 파이썬 pandas.melt() 데이터 재구조화(reshape) ( melt vs pivot ) (0) | 2021.10.13 |
| 파이썬 python replace 함수 치환 (0) | 2021.09.29 |
| 웹 사이트 주소 이해하고 requests와 BeautifulSoup으로 웹 크롤링 실습 (0) | 2021.08.02 |



