- 웹 크롤링(Web Crawling)
: 웹 크롤러가 자동으로 웹 페이지의 contents를 수집
-> HTML 페이지를 가져와서 HTML/CSS 등으로 원하는 데이터를 파싱/추출
- HTML 태그는 태그 이름 / 속성(attribute) 2가지로 구성됨
* 태그 이름 : 태그를 상징하는 <> 기호 안에 들어가는 정보 ex) p, li, img
* 속성 : 태그가 가진 추가정보. 속성 이름 & 속성 값이 하나의 쌍 ex) name = "value"
html_code = """<!DOCTYPE html>
<html>
<head>
<title>Sample Website</title>
</head>
<body>
<h2>HTML 연습!</h2>
<p>첫번째 문단: 파이썬 기본</p>
<p>두번째 문단: 웹 크롤링 기본</p>
<ul>
<li>web crawling</li>
<li>requests</li>
<li>BeautifulSoup</li>
</ul>
<img src='https://imgur.com/sYNJZWo.jpg' alt="python"/>
</body>
</html>""" # """으로 묶으면 여러 줄의 텍스트를 하나의 문자열로 인식>>>

>>>
html의 기본 구성은 다음 코드와 같다.
body 태그 안에 h2, p, ul, img 태그가 속해있고, ul 태그 안엔 li 태그가 종속되어 있는 형태이다. 태그 사이의 관계 중 부모관계 & 트리구조라 할 수 있는데 이 때 ul 태그는 부모이고 li 태그는 자녀이다.
그리고 하나의 태그를 끝낼 땐 태그 이름 앞에 슬래쉬( / ) 표시를 하며 끝낸다. ex) </p> 하지만 img 태그는 끝내주는 태그가 없다.
p 태그는 문단을 나타내는 'paragraph'의 p. 문단을 표시한다.
li 태그는 list item을 나타내서 리스트 요소 하나하나를 li 태그로 만들어준다.
- 웹 사이트 주소(URL) 해부

도메인은 사용자가 기억하기 쉽도록 문자로 표기된 이름이다. 컴퓨터와의 통신에서는 0.0.1.0 과 같은 ip 주소를 사용하기 때문에 이를 변환해 줄 네임 서버가 필요하다.
경로(path)는 /(슬래쉬) 뒤에 나온다. 로컬 서버의 문서에서 파일을 찾을 때 뜨는 문서 주소와 마찬가지로 컴퓨터 주소 경로를 나타낸다고 생각하면 편하다.
쿼리 스트링(parameter)은 'key = value' 형태로 이루어졌으며, & 로 연결하면 복수의 파라미터를 실행시킬 수 있다.
이미지의 "sorting = price" 는 상품의 정렬을 가격순으로 한다는 것이고, "PageNumber = 4"는 가격순으로 정렬한 상품의 4페이지로 가라는 일종의 명령어이다.
- requests 라이브러리
- HTTP 요청을 보낼 수 있는 기능을 제공하는 라이브러리. 서버로부터 응답을 요청하고 HTML 코드를 받음
- requests 모듈의 get() 함수는 응답 (Response) 객체를 돌려준다. 이 안에는 status_code도 있고 text, url, headers 등 다양하게 존재한다.
import requests
page=requests.get("https://fhaktj8-18.tistory.com/")
type(page)
>>>
requests.models.Response
>>>
page.text
>>>
'<!DOCTYPE html>\n<html lang="ko">\n <head>\n<link rel="stylesheet" type="text/css" href="https://t1.daumcdn.net/tistory_admin/lib/lightbox/css/lightbox.min.css" /><link rel="stylesheet" type="text/css" href="https://t1.daumcdn.net/tistory_admin/assets/blog/tistory-36f15cbcc77ea9489633a58757c4bb5d194ab57e/blogs/style/content/font.css?_version_=tistory-36f15cbcc77ea9489633a58757c4bb5d194ab57e" /><link rel="stylesheet" type="text/css" href="https://t1.daumcdn.net/tistory_admin/assets/blog/tistory-36f15cbcc77ea9489633a58757c4bb5d194ab57e/blogs/style/content/content.css?_version_=tistory-36f15cbcc77ea9489633a58757c4bb5d194ab57e" /><!--[if lt IE 9]><script src="https://t1.daumcdn.net/tistory_admin/lib/jquery/jquery-1.12.4.min.js">
...
>>>response된 객체의 요소들 중 text 요소를 불러오면 이렇게 html 코드의 텍스트가 불러와진다.
- BeautifulSoup
- 웹 페이지의 정보를 알아볼 수 있도록 파이썬 용어로 바꿔줘서 쉽게 스크랩을 할 수 있는 기능을 제공하는 라이브러리
from bs4 import BeautifulSoup
# 위에서 만들었던 html_code
soup = BeautifulSoup(html_code, 'html.parser')
print(type(soup))
>>>
<class 'bs4.BeautifulSoup'>
>>>html.parser 라든지 lxml 과 같은 parser 를 통해 파싱하게 되면, 파이썬 인터프리터가 해석할 수 있는 구조로 만들어주게 된다.
# 모든 <li> 태그 선택하기, 괄호 안에 CSS 선택자를 넣으면 특정 HTML 태그만 선택
li_tags = soup.select('li')
# 결과 출력, 리스트로 출력됨
print(li_tags)
>>>
[<li>web crawling</li>, <li>requests</li>, <li>BeautifulSoup</li>]
>>>
# 첫 번째 <li> 태그의 텍스트 출력하기, 해당 태그 안에 있는 텍스트만 추출
print(li_tags[0].text)
>>>
web crawling
>>>이렇게 select 함수를 활용해서 태그 안에 있는 텍스트를 추출하는 코드는 데이터 분석할 때 유용하게 활용되니 알아두는 게 좋다.
li 태그의 텍스트들을 모두 가져 온 리스트를 만들고 싶다면 for 반복문을 활용할 수 있다.
# 빈 리스트 만들기
study_names = []
# 텍스트 추출해서 리스트에 담기
for li in li_tags:
study_names.append(li.text)
# 결과 출력
print(study_names)
>>>
['web crawling', 'requests', 'BeautifulSoup']
실습: 순위권 영화 제목 가져오기
위에 코드를 활용해서 대표적인 영화 순위 사이트인 'IMDb'에 있는 'Top Rated Movies' 의 250개 영화 제목을 가져와보자.

페이지의 'Top Rated Movies' 카테고리를 클릭해서 들어가서 'ctrl+shift+i'를 하면 페이지의 html 코드를 볼 수 있는 검사 창이 뜬다. 아니면 마우스 우클릭->검사 클릭해도 실행됨.
검사 창의 왼쪽 위의 마우스 표시를 클릭하면 내가 원하는 위치에 마우스를 갖다 대면 해당하는 html 코드를 검사창에서 볼 수 있다.
1위 영화의 제목은 a 태그 안에 있다.
우선 코드 경로를 알아야 영화 제목 코드를 찾을 수 있으니 DOM을 살펴보자.
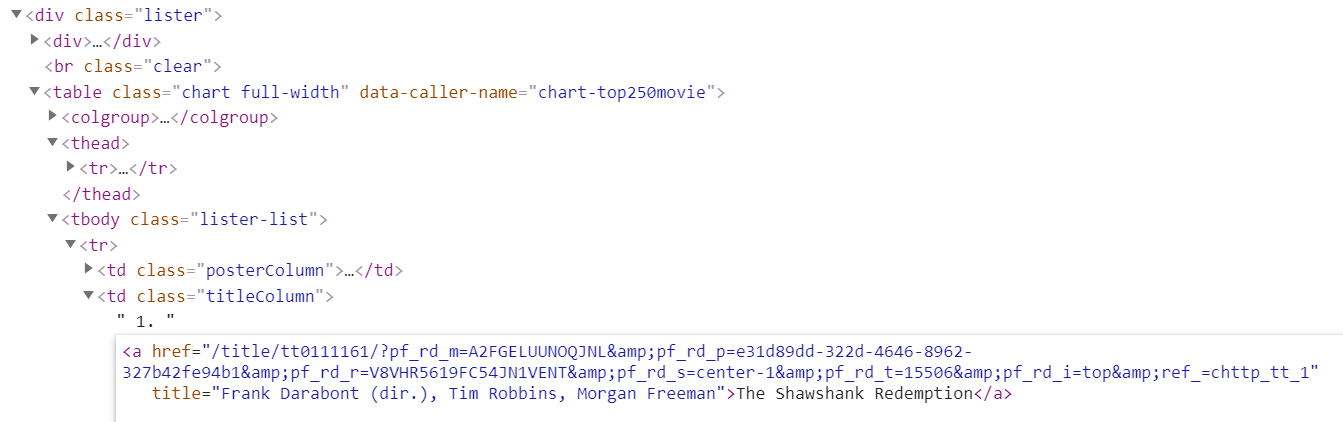
영화 제목인 "The Shawshank Redemption"은 a 태그로 감싸져 있고, a 태그는 td 태그의 "titleColumn" 클래스에 종속되어 있다. td 태그의 자식인 셈이니 'td.titleColumn>a'로 표기한다.
클래스의 상징기호인 '.'을 titleColumn 앞에 써주고,
'>'는 부모 바로 아래 자식 선택자에게만 스타일을 적용한다는 뜻이다.
계속해서 td는 tbody 태그에 종속되어 있고, tbody는 table 태그에 종속, table은 div에 종속되어 있다. 결국 div.lister를 뿌리로 해서 트리구조를 형성하고 있다.
이제 코드를 불러와서 BeautifulSoup을 활용하여 크롤링 해보자.
import requests
from bs4 import BeautifulSoup
movie_name = []
response4=requests.get("https://www.imdb.com/chart/top/?ref_=nv_mv_250")
soup4=BeautifulSoup(response4.text, "html.parser")
movie_tags=soup4.select('div.lister>table.chart.full-width>tbody.lister-list>tr>td.titleColumn>a')
for i in range(len(movie_tags)):
movie_name.append(movie_tags[i].text)
print(movie_name)
# for index, element in enumerate(movie_tags, 1):
# print("{} 위 영화: {}".format(index, element.text))여기서 중요한건 select의 파라미터로 영화 제목 html의 경로를 정확히 입력해줘야 원하는 텍스트가 추출된다.
경로 입력은 많이 연습해 보는게 답인 것 같다 :(
for 문에서 movie_tags의 길이만큼 for 문을 반복하면 i에는 movie_tags의 인덱스 수만큼 숫자가 대입된다.
movie_tags[i].text는 html 태그 안에 있는 영화 제목들을 차례로 추출하기 때문에 추출된 텍스트들을 movie_name 이라는 빈 리스트에 차례로 넣어줬다.
print(movie_name)은
['The Shawshank Redemption', 'Daeboo', 'The Godfather: Part II', 'The Dark Knight', '12 Angry Men', "Schindler's List", 'The Lord of the Rings: The Return of the King', 'Pulp Fiction', 'Il buono, il brutto, il cattivo', 'The Lord of the Rings: The Fellowship of the Ring', 'Fight Club', 'Forrest Gump', 'Inception', 'The Lord of the Rings: The Two Towers', 'Star Wars: Episode V - The Empire Strikes Back', 'The Matrix', 'Goodfellas', "One Flew Over the Cuckoo's Nest", 'Shichinin no samurai', º º º ]
이렇게 어마어마한 형태로 출력됐다..
몇 번째 순위 영화인지 한 눈에 알기 위해서 enumerate() 내장 함수를 사용했다.
enumerate는 반복문 사용시 몇 번째 반복문인지 확인할 때 유용하다.
인덱스 번호와 리스트의 원소를 튜플, 딕셔너리 형태로 반환한다.
enumerate( ['목록'], start = 1 ) 에서 start 인자에 1을 넣어주면 인덱스를 0이 아닌 1부터 시작한다. 우리가 알아보는 영화 순위 중엔 0순위가 없으니 start 인자 부분에 1을 넣어줬다.
>>>
1 위 영화: The Shawshank Redemption
2 위 영화: Daeboo
3 위 영화: The Godfather: Part II
4 위 영화: The Dark Knight
5 위 영화: 12 Angry Men
6 위 영화: Schindler's List
7 위 영화: The Lord of the Rings: The Return of the King
8 위 영화: Pulp Fiction
9 위 영화: Il buono, il brutto, il cattivo
10 위 영화: The Lord of the Rings: The Fellowship of the Ring
>>>
이렇게 url의 구조를 알아보고 requests와 BeautifulSoup을 이용해서 html을 파싱해보았다.
파싱한 정보들은 pd.DataFrame 메소드로 엑셀화할 수도 있다.
공부하면서 html 코드를 해부하고 영화 제목 코드의 경로를 찾는 게 가장 어려웠다. 자주 연습해야 할 것 같다 ㅠ
'Programming > python' 카테고리의 다른 글
| 파이썬 pandas.melt() 데이터 재구조화(reshape) ( melt vs pivot ) (0) | 2021.10.13 |
|---|---|
| 파이썬 python replace 함수 치환 (0) | 2021.09.29 |
| 파이썬 python matplotlib 으로 노년 구직자의 희망직종명 파이차트 그리기-2 (0) | 2021.07.22 |
| 파이썬 python drop, rename, isin 함수로 데이터 정제하기 -1 (0) | 2021.07.19 |
| 판다스 pandas IQR 활용해서 이상점(outlier) 찾고 삭제하기 (0) | 2021.07.12 |



