한글과 영어를 명령 프롬프트에서 혼용해서 출력할 때, 한글은 영어와 달리 2byte 문자이기 때문에 글자 사이의 너비가 불균형하게 출력된다. 어떤 프로그램을 만들 때 사용자로부터 입력받은 입력값이 제각각일 수 밖에 없는데 글자간 너비가 삐뚤빼뚤하다면 가독성이 떨어지고 보기도 안좋아서 이를 해소하기 위한 함수가 필요하다.
pcode = ['a001', 'a002', 'a003']
pname = ['블루투스스피커', 'monitor', '마우스']
qty = [100, 200, 300]
print("pcode----pname----------qty")
for pc, pn, qt in zip(pcode, pname, qty) :
print('{:<7} {:<10} {:<10}'.format(pc, pn, qt))
>>>
pcode----pname----------qty
a001 블루투스스피커 100
a002 monitor 200
a003 마우스 300위 결과를 보면 '블루투스스피커'와 'monitor' 모두 7글자지만 블루투스스피커가 2배 많은 공간을 차지한다.
'{:<10}' 으로 컬럼이 최대 10칸을 차지하도록 코딩하여 세 로우의 데이터가 고르게 출력되길 기대했지만, 한글과 영어가 혼용되어서 수직이 맞지 않는다.
이를 해결하기 위해 동아시아문자 폭을 고려하여 해당 문자열이 차지하는 너비를 계산하여 스페이스 문자의 길이를 계산해야 한다. 그리고 문자열 옆에 공백을 덧대어 간격을 맞춘다.
1. unicodedata.east_asian_width 를 이용한 포맷팅
- unicodedata.east_asian_width()의 인수로 문자를 넘겨주면 해당 문자가 어느 정도의 간격을 차지하는지 반환한다
- 실행결과
A: Ambiguous
F: Fullwidth
H: Halfwidth
N: Neutral
Na: Narrow
W: Wide
print(unicodedata.east_asian_width("블"))
>>>
W
print(unicodedata.east_asian_width("a"))
>>>
Na
print(unicodedata.east_asian_width("3"))
>>>
Na예를 들어, 인수로 "블" 문자를 넣으면 'W'가 반환된다. 한글 외의 알파벳, 숫자는 모두 'Na'가 반환된다.
아무래도 한글이 알파벳과 숫자보단 차지하는 byte가 많기 때문인 것 같다.
이 결과를 이용해서 한글 / 알파벳, 숫자로 구분해서 글자 뒤에 덧댈 공백의 수를 계산하는 함수를 작성해보자.
import unicodedata # 한글이 포함된 문자열에 간격 맞추기 솔루션을 제공하는 라이브러리
def preFormat(string, width, align='<', fill=' '):
count = (width - sum(1 + (unicodedata.east_asian_width(c) in "WF") for c in string))
return {
'>': lambda s: fill * count + s, # lambda 매개변수 : 표현식
'<': lambda s: s + fill * count,
'^': lambda s: fill * (count / 2)
+ s
+ fill * (count / 2 + count % 2)
}[align](string)- (unicodedata.east_asian_width(c) in "WF") 는 unicodedata.east_asian_width(c)의 결과가 "WF" 문자열에 존재하면 True, 아니면 False라는 bool 값을 반환한다. c가 한글이면 True로 반환되고, 알파벳이거나 숫자면 False를 반환한다.
- True는 1, False는 0이 되어 1에 더해진다. 만약 c가 한글이라면 1+1. 한글이 2 byte를 차지하기 때문에 1에 더해주는 것이다.
- for문을 돌리면 string의 모든 문자의 자릿수가 합쳐지고 이를 총 자릿수인 width에서 뺀다.
- fill * count로 공백의 수를 구하고, lambda 함수로 매개변수 s의 정렬 배치를 설정한다.
- 리턴문은 딕셔너리의 key 값을 이용해 value를 불러오고, s 매개변수에 string을 대입하는 코드임
2. wcwidth 를 이용한 포맷팅
from wcwidth import wcswidth
print('블루투스스피커 자릿수 --> ',wcswidth('블루투스스피커'))
print('monitor 자릿수 --> ',wcswidth('monitor'))
>>>
블루투스스피커 자릿수 --> 14
monitor 자릿수 --> 7wcwidth 모듈의 wcswidth 함수의 인수로 문자열을 넣으면 그 문자열의 자릿수를 반환한다.
한글은 2byte를 차지해서 블루투스스피커와 monitor의 글자 수는 같지만, 블루투스스피커가 monitor보다 2배 더 자릿수를 차지한다는 걸 확인했다.
from wcwidth import wcswidth # 한글이 포함된 문자열에 간격 맞추기 솔루션을 제공하는 라이브러리
def fmt(x, w, align='r'): # align의 기본값은 'r : right'
""" 동아시아문자 폭을 고려하여, 문자열 포매팅을 해 주는 함수.
w 는 해당 문자열과 스페이스문자가 차지하는 너비.
align 은 문자열의 수평방향 정렬 좌/우/중간.
"""
x = str(x) # 해당 문자열
l = wcswidth(x) # 문자열이 몇자리를 차지하는지를 계산.
s = w-l # 남은 너비 = 사용자가 지정한 전체 너비 - 문자열이 차지하는 너비
if s <= 0:
return x
if align == 'l':
return x + ' '*s
if align == 'c':
sl = s//2 # 변수 좌측
sr = s - sl # 변수 우측
return ' '*sl + x + ' '*sr
return ' '*s + x- 남은 너비 s가 0보다 작다면 그대로 변수 x를 리턴한다.
- 만약 align이 'l' (left)라면 변수 x 우측에 공백을 s만큼 추가하여 리턴한다.
- 만약 align이 'c' (center)라면 변수 좌측 공백 + 변수 x + 변수 우측 공백을 리턴한다.
- 만약 align이 기본값 'r' (right)라면 변수좌측에 남은 너비만큼 공백을 더해서 리턴한다.
* 전체보기 *
import unicodedata # 한글이 포함된 문자열에 간격 맞추기 솔루션을 제공하는 라이브러리
from wcwidth import wcswidth # 한글이 포함된 문자열에 간격 맞추기 솔루션을 제공하는 라이브러리
def preFormat(string, width, align='<', fill=' '):
count = (width - sum(1 + (unicodedata.east_asian_width(c) in "WF") for c in string))
return {
'>': lambda s: fill * count + s, # lambda 매개변수 : 표현식
'<': lambda s: s + fill * count,
'^': lambda s: fill * (count / 2)
+ s
+ fill * (count / 2 + count % 2)
}[align](string)
def fmt(x, w, align='r'): # align의 기본값은 'r : right'
""" 동아시아문자 폭을 고려하여, 문자열 포매팅을 해 주는 함수.
w 는 해당 문자열과 스페이스문자가 차지하는 너비.
align 은 문자열의 수평방향 정렬 좌/우/중간.
"""
x = str(x) # 해당 문자열
l = wcswidth(x) # 문자열이 몇자리를 차지하는지를 계산.
s = w-l # 남은 너비 = 사용자가 지정한 전체 너비 - 문자열이 차지하는 너비
if s <= 0:
return x
if align == 'l':
return x + ' '*s
if align == 'c':
sl = s//2 # 변수 좌측
sr = s - sl # 변수 우측
return ' '*sl + x + ' '*sr
return ' '*s + x
pcode = ['a001', 'a002', 'a003']
pname = ['블루투스스피커', 'monitor', '마우스']
qty = [100, 200, 300]
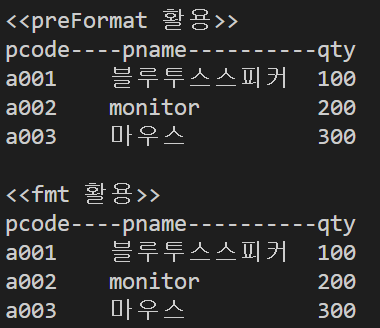
print("<<preFormat 활용>>")
print("pcode----pname----------qty")
for pc, pn, qt in zip(pcode, pname, qty) :
print('{} {} {}'.format(preFormat(pc,7), preFormat(pn,15), preFormat(str(qt), 10)))
print("\n<<fmt 활용>>")
print("pcode----pname----------qty")
for pc, pn, qt in zip(pcode, pname, qty) :
print('{} {} {}'.format(fmt(pc,7,'l'), fmt(pn,15,'l'), fmt(str(qt), 10,'l')))>>>
'Programming > python' 카테고리의 다른 글
| 파이썬으로 엑셀 파일이 안 불러와질 때 할 수 있는 방법 (리눅스 환경) (3) | 2023.10.31 |
|---|---|
| 파이썬 메서드 오버라이딩(Overriding) vs 오버로딩(Overloading) (0) | 2022.10.14 |
| [오픈 API] 공공 데이터 주소 활용하여 위도, 경도 좌표 찾기 (2) | 2022.07.26 |
| 클래스(class)와 객체 지향 프로그래밍(object oriented programming) 개념 정리 (0) | 2022.06.13 |
| 파이썬 선택 정렬 알고리즘(selection sort) 개념과 예제 (0) | 2022.06.06 |



